Overview
AI-Counselling is a full-stack, production-grade multimodal AI companion that delivers empathetic mental-health support across text, voice, and video. I designed and built the entire system end-to-end: a Next.js 15 / React 19 frontend authenticated via Clerk, a FastAPI inference backend running on Python 3.12, MongoDB Atlas for persistence, and Google Cloud Storage for media. The backend orchestrates six distinct AI/ML components — Google Gemini 2.5 Flash for generation, FAISS-backed DSM-5 retrieval, Wav2Vec2 ensemble speech-emotion recognition, DeepFace facial-emotion analysis, Google Speech-to-Text, and Google Cloud Text-to-Speech — behind a single conversational interface.
Engineering-wise, the system is a real-time multimodal fusion pipeline: raw audio and video streams are normalized, transcribed, and converted into structured signals (transcripts, emotion labels, ensemble confidence scores, tone phases), then fused with a retrieval layer and a per-user long-term memory store before being injected into a structured LLM prompt. The result is a system that listens, watches, remembers, and responds — with crisis-keyword safety rails, small-talk routing, and strict prompt-level style constraints baked in.
Problem and Goal
Most mental-health software either gates users behind clinician availability or hands them a static chatbot that ignores what they actually look and sound like. I set out to build something better: a low-friction, multimodal companion that captures emotional context the way a human listener would — through words, tone, and facial expression — and grounds its responses in a clinical reference (the DSM-5) rather than free-form hallucination. The system is explicitly scoped as a complement to professional care, with hardcoded safety responses for crisis keywords and a prompt policy that forbids medical advice.
Core User Experience
On first sign-in via Clerk, users complete a multi-step onboarding wizard built in React that captures age range, presenting concerns, goals, DSM-5-aligned cross-cutting symptom scales, functional impairment, substance use, and preferred interaction mode. This structured profile is persisted to MongoDB through a Clerk webhook and surfaced to every downstream LLM call as personalization context.
- Text: A streaming React chat UI calls
POST /respond, which routes to a small-talk shortcut or a full RAG + memory + history prompt depending on intent. - Voice: A custom React hook records WebM audio in fixed-duration chunks and uploads them to GCS under per-user prefixes; the backend ingests recent chunks, runs tone analysis and STT, and returns a synthesized voice reply.
- Video: The browser captures camera + mic via the MediaRecorder API and uploads the WebM blob to FastAPI, which performs frame-sampled facial-emotion detection alongside the voice pipeline for full multimodal fusion.
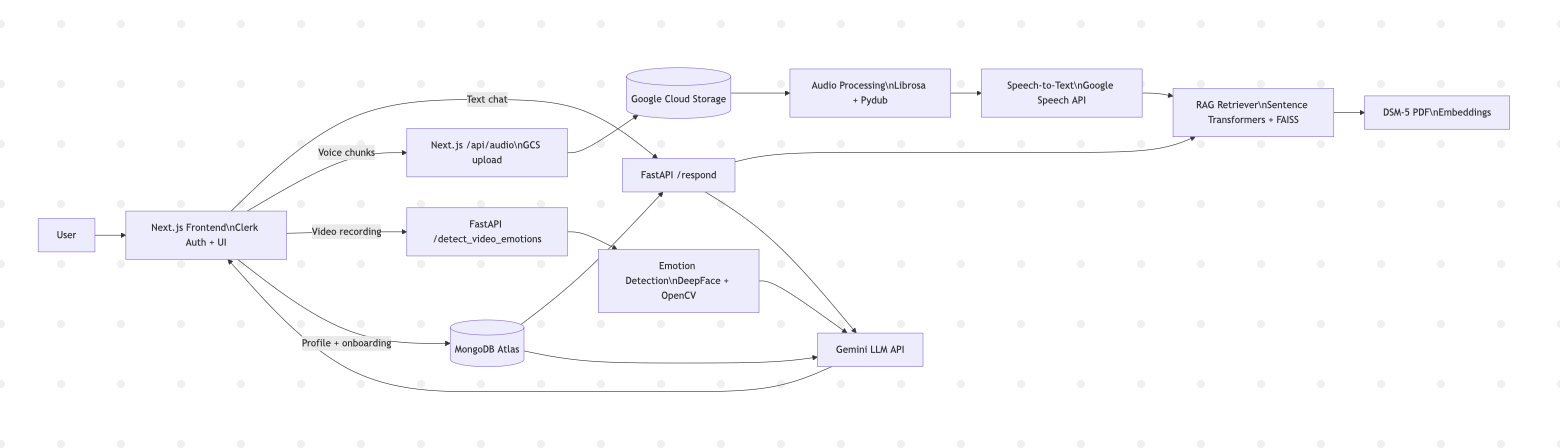
System Architecture
The platform is split across three deployable services: a Next.js frontend (Vercel-ready, also containerized via
Dockerfile.frontend), a FastAPI inference backend (containerized via Dockerfile, orchestrated locally with
docker-compose), and managed cloud dependencies (MongoDB Atlas, Google Cloud Storage, Google Generative AI,
Google Speech/TTS). Authentication is handled by Clerk on both client and server, with a webhook route under
/api/webhooks/clerk that syncs user lifecycle events into MongoDB. All media writes are namespaced under
users/<clerk_user_id>/ prefixes in GCS for tenant isolation.
Retrieval-Augmented Generation over the DSM-5
To keep responses grounded and reduce hallucination risk, the system uses the full DSM-5 (Diagnostic and Statistical Manual of Mental Disorders) as a clinical knowledge base. I built a custom RAG pipeline rather than calling a hosted vector DB, which keeps the system self-contained and removes per-query network latency.
Indexing: The PDF is parsed with PyPDF2, split into overlapping word windows
(400 words per chunk with 80-word overlap to preserve cross-section context), and embedded with the
all-mpnet-base-v2 Sentence Transformer (768-dim). Embeddings are L2-normalized and persisted to disk alongside a
manifest hash of the model, chunk size, overlap, and PDF byte size — the index auto-rebuilds only when one of those
inputs changes, eliminating cold-start cost on every deploy.
Retrieval: Queries are encoded and searched against a FAISS IndexFlatIP (cosine similarity via inner product
on normalized vectors), returning the top-5 chunks above a 0.25 similarity floor — empirically chosen to filter
irrelevant matches while still recovering relevant clinical context. The index is loaded once at process startup and
held in memory for the lifetime of the FastAPI worker.
Voice Analysis Pipeline
The voice path stitches together browser-side recording, GCS storage, and a multi-stage Python audio pipeline. A
custom React hook (useAudioChunkUploader) records WebM audio frames in the browser and streams them to GCS via a
Next.js API route, which authenticates the user with Clerk and writes to users/<id>/audio/webm/.
Signal Processing: The backend lists recent objects, decodes them with Librosa (FFmpeg-backed for WebM), resamples to 16 kHz mono, applies a 100 Hz–8 kHz band-pass via pydub, and runs peak normalization plus dynamic-range compression (4:1 ratio, -20 dB threshold) for stable downstream feature extraction.
Ensemble Emotion Recognition: Audio is windowed into overlapping 1-second chunks (0.5 s overlap) and
gated by a voice-activity heuristic that checks RMS energy, zero-crossing rate, and spectral centroid to skip silence
and noise. Each surviving chunk is run through a Wav2Vec2 sequence classifier
(r-f/wav2vec-english-speech-emotion-recognition) multiple times per chunk, and predictions are aggregated by
majority vote weighted by softmax confidence. Adjacent same-emotion chunks are then merged into phases, producing
a structured tone summary (phases, per-emotion duration distribution, total duration, and mean confidence) that the
LLM consumes as signal — not a single label.
Speech-to-Text Robustness
Real-world browser audio is messy: chunks can be truncated, codecs vary, and pydub frequently fails to decode partial
WebM frames. I built a fault-tolerant transcription path that falls back to a tolerant FFmpeg CLI transcode
(-err_detect ignore_err) when pydub raises, salvaging partial WAV bytes from non-zero exits rather than dropping the
chunk. Preprocessed audio is split into 50-second segments (Google STT's practical sweet spot) and submitted to
the SpeechRecognition library, with per-segment retries and best-alternative selection by confidence. A process-level
cache of already-transcribed GCS keys prevents the same chunk from being re-processed across requests.
Video Emotion Detection
Uploaded video is decoded with OpenCV. Rather than analyzing every frame, the pipeline samples at ~1 fps up to a 60-frame cap, computing a stride from the source FPS, which keeps end-to-end latency bounded regardless of clip length.
Each sampled frame is run through DeepFace with enforce_detection=False so motion blur or off-angle frames
degrade gracefully into a "No face" label instead of throwing. Per-frame labels are aggregated by frequency to produce
a dominant emotion, and the frontend can additionally pre-compute frame-level emotions in-browser and pass them to the
backend via the client_emotions form field — a hybrid edge/server design that lets the backend skip redundant inference
when the client has already done the work.
Long-Term Memory & Conversation State
Short-term memory comes from the most recent 10 chat-history records pulled from MongoDB on every request. Long-term
memory is implemented as a lazy Gemini-driven user profile summarizer: after each message, the system updates a
profile_summary field on the user document, condensing the new turn into a structured psychological profile (core
issues, current state, key facts) while retaining stable long-term signals like prior diagnoses or major life events.
This gives the assistant continuity across sessions without unbounded context growth, and keeps the per-request prompt
size predictable.
LLM Prompting, Routing & Safety
The orchestration layer fuses five distinct signals — user transcript, facial-emotion summary, Wav2Vec2 tone phases, DSM-5 retrieval chunks, onboarding profile, recent chat history, and long-term memory summary — into a single structured Gemini 2.5 Flash prompt with explicit style rules (match the user's energy, cap at 3 sentences, never give medical advice, never lecture).
Two routing layers sit in front of generation: a crisis-keyword detector short-circuits to a hardcoded safety response (with emergency-resource framing) when self-harm terms appear, and a small-talk classifier swaps in a lightweight conversational prompt that suppresses any clinical or analytical content — so a casual "hi" gets a casual reply, not a therapy framework.
Data Strategy, APIs & Output
MongoDB holds user profiles, onboarding questionnaires, chat history, audio frame metadata (with SHA-256 checksums), and the long-term profile summaries. GCS holds all binary media under per-user prefixes. Generated responses are run through Google Cloud Text-to-Speech (Journey voice with a Wavenet fallback) and returned as base-64 MP3 so the frontend can play replies inline without a second round-trip.
The backend exposes modality-specific endpoints, each fully composable with the shared RAG + memory + safety stack:
POST /respond— text chat with crisis routing, small-talk routing, RAG context, recent history, and long-term memory.POST /detect_video_emotions— accepts a video upload, runs facial-emotion sampling + tone analysis + STT + Gemini fusion.POST /process_multimodal— combines GCS-stored voice frames with frontend-collected video emotions for low-latency multimodal turns.GET /process_speech— batch-processes a user's recent GCS audio chunks and returns transcript, tone, response, and TTS audio.POST /analyze_frame— single-frame DeepFace inference for live edge-side emotion previews.POST /api/audio&POST /api/uploadVideo— Clerk-authenticated Next.js routes that stream media into GCS.POST /api/webhooks/clerk— verifies Svix-signed Clerk webhooks and syncs user lifecycle into MongoDB.
Engineering Challenges Solved
- Partial-WebM decoding: Browser MediaRecorder frequently produces truncated chunks that crash pydub. Built a graceful FFmpeg-backed fallback that salvages partial WAV output, raising the transcription success rate on real recordings.
- Per-frame Wav2Vec2 variance: Single-pass emotion predictions were noisy. Designed a multi-run ensemble with majority voting and confidence weighting on top of a voice-activity heuristic, producing stable per-phase labels instead of a flickering single emotion.
- RAG cold starts: Naively rebuilding embeddings on every deploy is unacceptable. Implemented manifest-hashed index caching keyed on model name, chunk config, and PDF size — the index rebuilds only when something materially changes.
- Unbounded conversation context: Stuffing full history into every prompt explodes cost and latency. Solved with a Gemini-summarized rolling user profile, separating long-term identity from short-term turn context.
- Off-topic clinical responses to small talk: Early prototypes responded to "hi" with therapy frameworks. Added a small-talk classifier and a separate, strict casual-reply prompt path.
- Crisis safety: Implemented deterministic keyword routing that bypasses the LLM entirely for self-harm indicators, returning a fixed, professionally-framed safety response — no model output, no risk of an unsafe completion.
Tech Stack
- Frontend: Next.js 15 (App Router), React 19, TypeScript, Tailwind CSS, Clerk (auth + webhooks), MediaRecorder API.
- Backend: FastAPI, Uvicorn, Python 3.12, Pydantic, structured logging with stdout/stderr redirection.
- AI / ML: Google Gemini 2.5 Flash, Wav2Vec2 (HuggingFace Transformers + PyTorch), DeepFace, Sentence Transformers (
all-mpnet-base-v2), FAISS (IndexFlatIP). - Speech & Audio: Librosa, pydub, FFmpeg, Google SpeechRecognition, Google Cloud Text-to-Speech.
- Vision: OpenCV for frame sampling and decoding.
- Data & Storage: MongoDB Atlas (PyMongo + Mongoose), Google Cloud Storage with Application Default Credentials.
- Infra & DevOps: Dockerfile + Dockerfile.frontend, docker-compose, Vercel deployment config, pre-commit hooks, ESLint.
The ML stack is intentionally modular: every modality emits interpretable intermediate outputs (transcripts, emotion phases, retrieval chunks, memory summary) that are logged and swappable, so any single component can be replaced or upgraded without rebuilding the rest of the system.
Outcomes & Impact
- Shipped a working, end-to-end multimodal AI product spanning frontend, backend, ML, data, and cloud infrastructure — designed, implemented, and deployed solo.
- Integrated 6 distinct AI/ML systems (Gemini, Wav2Vec2, DeepFace, MPNet/FAISS RAG, Google STT, Google TTS) behind a single conversational interface with shared safety and personalization layers.
- Built a fault-tolerant audio pipeline that recovers from partial browser uploads via FFmpeg salvage, eliminating a major real-world failure mode.
- Reduced inference latency on video turns by sampling frames at ~1 fps with a 60-frame cap and supporting client-side emotion pre-computation, avoiding redundant DeepFace inference server-side.
- Designed a self-contained vector index with manifest-hashed cache invalidation, removing external vector-DB dependencies and keeping retrieval entirely in-process.
- [ADD PROJECT METRIC HERE — e.g., active users, average response latency, total recorded sessions, or hackathon/competition outcome.]
Conclusion
AI-Counselling is the project I'd point to as the clearest demonstration of my ability to ship a serious AI system end-to-end: product thinking around a sensitive problem space, applied ML across audio / vision / language, a real cloud architecture with auth and persistence, and the engineering discipline to handle the messy edges (partial uploads, noisy predictions, safety routing, cache invalidation) that separate a working demo from something that could responsibly be put in front of users.