Overview
This project provides an annotated implementation of the Vision Transformer (ViT) model based on the paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" (Dosovitskiy et al., ICLR 2021). While Convolutional Neural Networks (CNNs) have long dominated computer vision, this project explores how Transformers—originally designed for NLP—can be applied directly to image sequences. We demonstrate the implementation from the ground up and analyze its performance when trained from scratch on the CIFAR-10 dataset.
Background
For decades, CNNs like ResNet and VGG have been the standard for vision tasks due to their built-in inductive biases:
- Locality: Convolutions operate on local neighborhoods of pixels.
- Translation Equivariance: Features detected in one location can be recognized elsewhere.
- Hierarchical Features: Stacking layers builds from edges to textures to objects.
However, the Transformer revolution in NLP (BERT, GPT) showed that massive datasets and self-attention mechanisms could outperform hand-crafted priors. The Vision Transformer paper made a simple but powerful observation: Treat image patches as tokens.
Key findings from the paper indicate that while ViT underperforms ResNets on small datasets (due to lack of inductive bias), it achieves state-of-the-art results when pre-trained on massive datasets (like JFT-300M), effectively learning the spatial relationships that CNNs have hard-coded.
Model Architecture
The ViT architecture consists of several specific components designed to map image data into a sequence format compatible with standard Transformers.
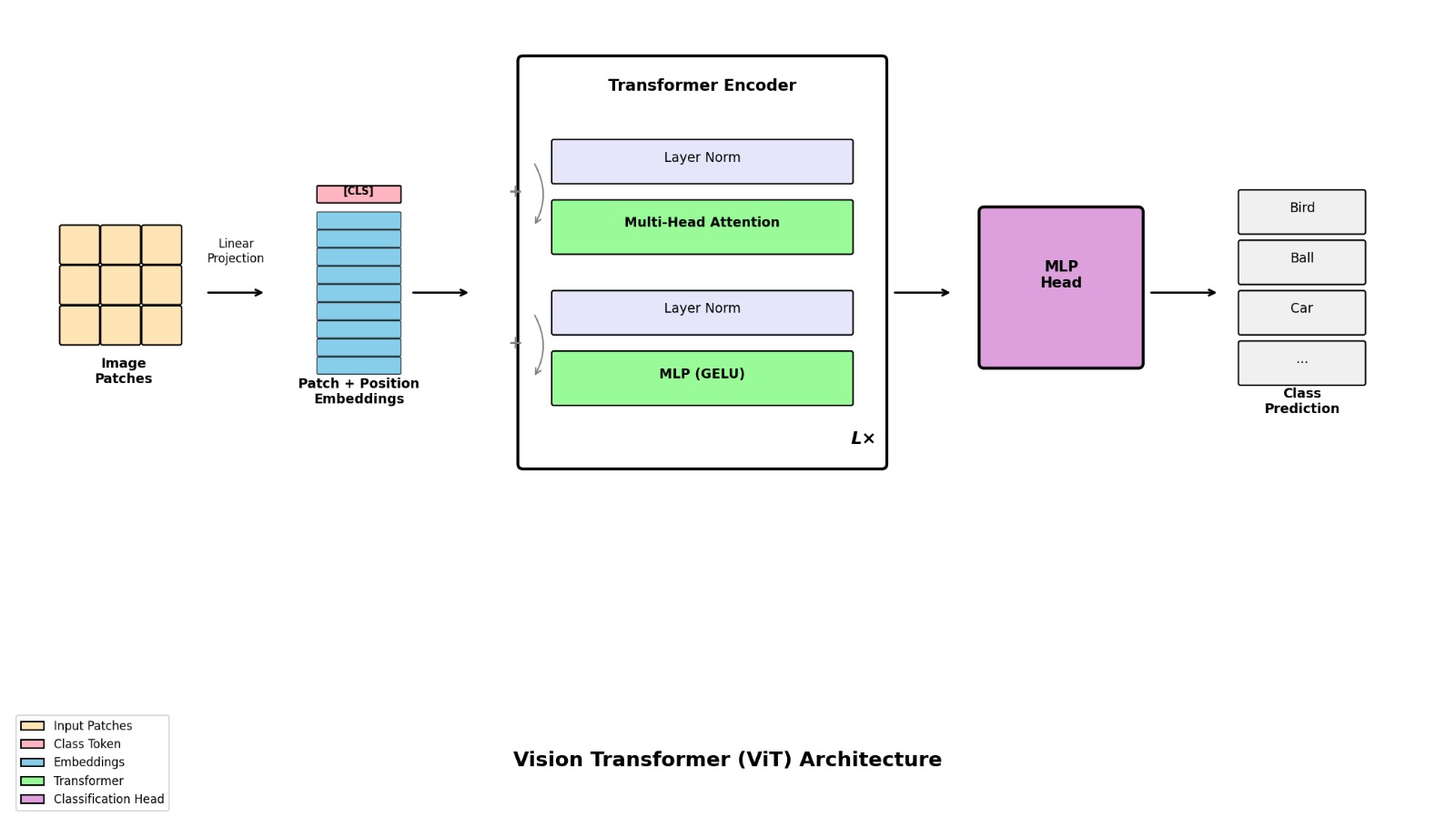
1. Patch Embedding
The first step converts an image into a sequence. We split the image into fixed-size patches and project them to an embedding dimension. In our implementation, we use a Conv2d layer with kernel size and stride equal to the patch size to perform this extraction and projection simultaneously.
class PatchEmbedding(nn.Module):
def __init__(self, in_channels=3, embed_dim=768, patch_size=16):
super().__init__()
self.proj = nn.Conv2d(in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # (B, Embed, H/P, W/P)
x = x.flatten(2) # (B, Embed, N)
x = x.transpose(1, 2) # (B, N, Embed)
return x2. Class Token & Position Embedding
Following BERT, ViT prepends a learnable [CLS] token to the patch embeddings. This token aggregates information from the entire sequence via self-attention. Additionally, since Transformers have no inherent notion of order, learnable 1D position embeddings are added to the sequence to retain spatial information.
class ClassToken(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
def forward(self, x):
B = x.shape[0]
cls_tokens = self.cls_token.expand(B, -1, -1)
return torch.cat((cls_tokens, x), dim=1)3. Transformer Encoder
The core is a standard Transformer encoder using a Pre-Norm architecture...
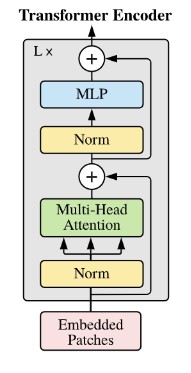
class TransformerEncoderBlock(nn.Module):
def __init__(self, embed_dim, num_heads, mlp_ratio=4, dropout=0.0):
super().__init__()
self.ln1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads,
dropout=dropout, batch_first=True)
self.ln2 = nn.LayerNorm(embed_dim)
hidden_dim = int(embed_dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
x_norm = self.ln1(x)
attn_out, _ = self.attn(x_norm, x_norm, x_norm)
x = x + attn_out # Residual
x_norm = self.ln2(x)
mlp_out = self.mlp(x_norm)
x = x + mlp_out # Residual
return x4. Classification Head
Finally, a classification head maps the [CLS] token's representation to the output classes. While the original paper uses an MLP during pre-training, we use a single linear layer for our CIFAR-10 model to act as a structural regularizer and prevent overfitting.
Inference Pipeline
Once trained, the inference process is straightforward. We implemented a pipeline that takes an image, processes it through the transformer, and outputs probabilities.
- Input: Image tensor of shape (B, C, H, W).
- Patching: Image is split into patches and projected.
- Tokens: [CLS] token prepended; Position embeddings added.
- Encoder: Sequence passes through L layers of attention.
- Prediction: [CLS] token is extracted and projected to class logits.
@torch.no_grad()
def predict(model, image, device):
model.eval()
image = image.to(device)
if image.dim() == 3: image = image.unsqueeze(0)
logits = model(image)
probs = F.softmax(logits, dim=1)
pred_class = logits.argmax(dim=1)
return pred_class, probsExperimental Setup (Mini-ViT)
To demonstrate feasibility on consumer hardware (CPU/Laptop), we trained a miniaturized version of ViT on the CIFAR-10 dataset. The original ViT-Base is too large for this scale of data, so we adapted the architecture:
Model Config
- Image Size: 32x32 (vs 224)
- Patch Size: 4x4 (64 patches)
- Depth: 4 Layers
- Embed Dim: 128
- Heads: 4
Training Config
- Epochs: 20
- Optimizer: AdamW
- Learning Rate: 3e-4
- Schedule: Warmup + Cosine Decay
- Augmentation: RandomCrop, Flip
def train_one_epoch(model, loader, criterion, optimizer, device):
model.train()
total_loss, correct, total = 0.0, 0, 0
for images, labels in loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item() * images.size(0)
correct += outputs.argmax(1).eq(labels).sum().item()
total += labels.size(0)
return total_loss / total, 100.0 * correct / totalResults & Analysis
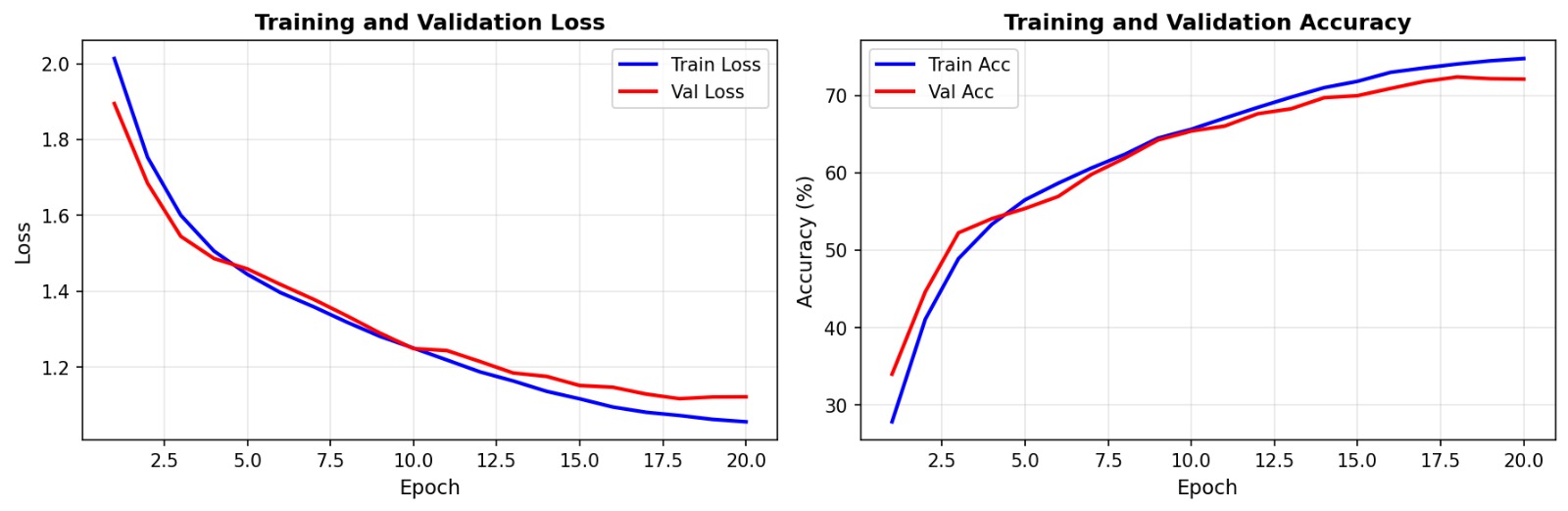
The training curves reveal a significant gap between Training Accuracy (80.23%) and Validation Accuracy (71.68%). This overfitting is expected and highlights the primary limitation of Vision Transformers: Data Hunger.

Why does Mini-ViT underperform compared to CNNs on CIFAR-10?
- Lack of Inductive Biases: CNNs inherently understand locality and translation. ViT must learn these spatial concepts from scratch, which is difficult with only 50k images.
- Low Resolution: At 32x32 resolution with 4x4 patches, the model only has 64 tokens to work with. This limits the "long-range" context that self-attention is designed to exploit.
- No Pre-training: ViT relies heavily on large-scale pre-training (ImageNet-21k, JFT-300M) to learn robust features. Training from scratch on a small dataset yields suboptimal results compared to Transfer Learning.
Discussion
Strengths:
- Scalability: ViT scales significantly better than CNNs as data and compute increase.
- Global Attention: Can capture relationships between distant parts of an image in the very first layer.
- Simplicity: Uses a standard Transformer encoder without complex vision-specific operators.
Weaknesses:
- Quadratic Complexity: Attention costs grow quadratically with the number of patches, limiting high-resolution applications.
- Data Inefficiency: Requires massive datasets to beat CNN baselines.
Conclusion: This project successfully implemented a functional Vision Transformer from scratch. While the Mini-ViT did not break state-of-the-art records on CIFAR-10, it effectively demonstrated the mechanics of patch embedding, positional encoding, and self-attention in a computer vision context. Future work involves exploring data-efficient training recipes (like DeiT) or hybrid CNN-Transformer architectures.